About N2T.net
N2T.net (Name-to-Thing) is a "resolver," a kind of server that specializes in indirection. Resolvers serve content indirectly by forwarding most incoming requests to other servers rather than serving content directly (this page being an exception). Resolvers are good at redirecting requests to content servers, similar to URL shorteners like bit.ly and t.co.
Origins of N2T
The name "n2t" was chosen for several reasons. First, it is unique enough to be easy to search for. Second, "n2t" is relatively opaque, which helps URLs based at n2t.net to age and travel well, the presumption being that brand- and language-neutrality can shield URLs from future embarrassment and forced retirement due to long term evolving political, legal, and usability pressures. The name is also short, which saves time and space – both in storage and in "visual real estate" – across often-repeated acts of transcription and citation. Finally, N2T's name was patterned after a set of IETF (the main Internet standards body) mapping operations for the URN (Uniform Resource Name) dating back to 1997 (RFC 2168): N2R (Name to Resource), N2L (Name to URL), and N2C (Name to URC, 'C' = Characteristics/Citation).
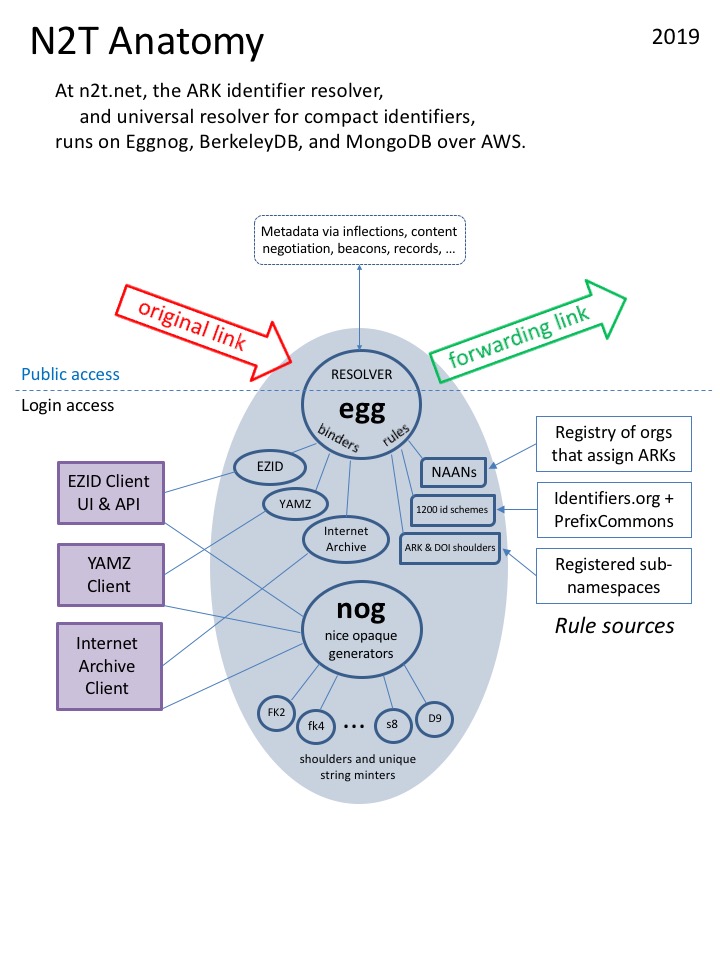
N2T's technical infrastructure arose from the demand for a global ARK (Archival Resource Key) resolver. All that a basic resolver needs is software to look up a given incoming string in a table and to issue a "server redirect", as found in every web server since 1992. The approach taken by many systems (Handle, DOI, etc.), is to create a "silo" that only works for one type of identifier. Because making lookups fail except for certain parts of the alphabet is exclusionary and artificial, the ARK resolver design took a more open and general approach. The result was N2T, a scheme-agnostic resolver that currently works for over 900 types of identifier, including ARKs, DOIs, Handles, PURLs, URNs, ORCIDs, ISSNs, etc.
The main use of N2T is for "persistent identifiers". An archive or publisher that gives out content links (URLs) starting with n2t.net doesn't need to worry about their breaking when content eventually moves to different servers. Provided forwarding rules at N2T are updated, links starting with n2t.net remain stable. (All persistent identifier systems rely on this same basic principle.)
Features Unique to the N2T Resolver
Unlike URL shorteners, N2T can store more than one "target" (forwarding link) for an identifier, as well as any kind or amount of metadata (descriptive information) and links to metadata in different formats. When forwarding doesn't work for some reason, such as a temporary outage or insufficient permission at the target server, N2T can nonetheless return any persistent information it has about the identified object. N2T also supports CORS (Cross-Origin Resource Sharing) to securely enable JavaScript access to public content with identifiers based at N2T. Some other unique features:
Suffix passthrough. N2T supports "suffix passthrough", which drastically reduces the number of individual identifiers that providers need to maintain.
Inflections. It supports "inflections" and "content negotiation", which allow you to request descriptive information for identifiers that have it.
Identifier-scheme-agnostic. N2T.net is unusual among resolvers because it is not a silo that works with only one kind of identifier. It stores individual identifiers of any kind, including both ARKs and DOIs, and provides equal services to all kinds, regardless of origin.
Cross-scheme features. As a result N2T easily supports feature combinations that some find surprising, such as ARK-style inflections for DOIs, and ARKs that return DataCite DOI metadata via content negotiation.
Resolver and meta-resolver. Unusually, N2T is a "meta-resolver" (like identifiers.org), but at the same time it stores about 50 million identifiers. As a meta-resolver, it recognizes over 900 well-known identifier types, including all those known to identifiers.org, and knows where their respective servers are. Failing to find forwarding information for an identifier that it looks up (in its regular resolver role), it assumes its meta-resolver role and uses the identifier's type to look for an overall "target rule".
NLID substitution. N2T has a special target rule substitution feature for an identifier with a NAAN-like component (ARK, DOI, URN, Handle). Wherever the string ${nlid} appears in the target string, the NLID (NAAN-local identifier), which is everything to the right of the NAAN, will be substituted. It is best if the forwarding URL ends up showing the "compact id" (eg, the part starting "ark:"), but the NLID is useful since it is the identifier part over which most identifier creators have direct control. While it is easy for a web server to recognize an incoming NAAN, it still requires a one-time webmaster action, and that may not be feasible. The ${nlid} substitution feature obviates that need because with a target rule such as
https://mysite.example.org/blog/${nlid}N2T will forward an ARK such as ark:/12345/67890 directly to
https://mysite.example.org/blog/67890
instead of forwarding it to (using the compact ARK)
https://mysite.example.org/ark:/12345/67890
which avoids an extra local web server configuration step.
Prefix extension. N2T supports a "prefix extension" feature that permits developers to extend a scheme or an ARK NAAN (both of which "prefix" an identifier) with -dev in order to forward to an alternate destination. For example, if the NAAN 12345 forwards to domain a.b.org, then ark:/12345-dev/678 forwards to a-dev.b.org/678. It works similarly for schemes, for example, if scheme xyzzy forwards to a.b.org/$id, then xyzzy-dev:foo forwards to a-dev.b.org/foo.
Audience
The primary audience for N2T services is the global community of people engaged in research, academic, and cultural heritage endeavors. Together with our primary partners, EZID and Internet Archive, we work with national, university, and public libraries, academic and society publishers, natural history and art museums, as well as companies and funders that support education and research.
N2T identifiers are used for everything from citing scholarly works to referencing tissue samples. They link to cutting edge scientific datasets, historic botanists, evolving semantic web term definitions, living people, and many other things.
Organizational Backing
N2T is maintained at the California Digital Library (CDL) within the University of California (UC) Office of the President (UCOP). CDL supports electronic library services for ten UC campuses and affiliated law schools, medical centers, and national laboratories, as well as hundreds of museums, herbaria, botanical gardens, etc. You may provide feedback on N2T via the CDL contact form.
N2T runs in the AWS (Amazon Web Services) cloud. On top of the foundational physical, network, and procedural security maintained by AWS datacenters located in the United States of America, N2T security and privacy is enhanced by additional CDL and UCOP privacy safeguards, patching policies, access restrictions, and firewall controls,
N2T is a critical piece of global infrastructure under the purview of the ARK Alliance. Founded by the CDL and LYRASIS, the ARK Alliance now enjoys the support of some 40 institutions.
Maintenance Window
The N2T service may occasionally be suspended or interrupted for up to one hour during the routine maintenance window. If maintenance is to take place, it happens on Sundays beginning at 08:00 in California, UTC-08:00 (standard time), UTC-07:00 (daylight savings).
{kind=link}